Постановка проблеми. В тезах розглядається алгоритм та програмна реалізація науково-дослідного модулю підсистеми дистрибутивно-семантичного аналізу природномовних текстових документів українською мовою та виділення і кластеризація наявних понять. В рамках запропонованого підходу до текстів природною мовою застосовується впорядкований набір універсальних процедур, що дозволяє виділити основні одиниці мови (слова, словосполучення), провести їх класифікацію, кластеризацію та визначити поняття в текстовому документі.
Мета дослідження. Розробити сервіс (алгоритм та програмну реалізацію) науково-дослідного модулю підсистеми дистрибутивно-семантичного аналізу текстових документів українською мовою та виділення і кластеризацію наявних понять, з використанням алгоритмів word2vec та MajorClust.
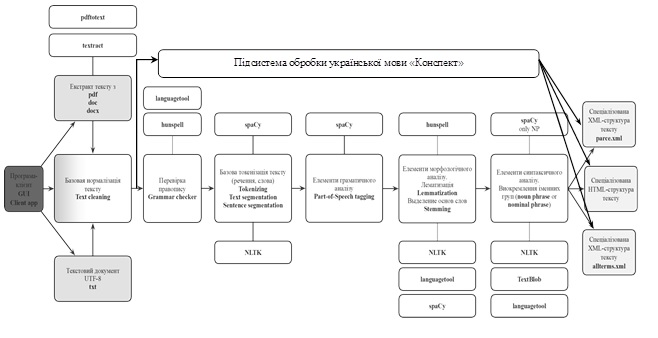
Результати дослідження. Автоматизований аналіз текстів природною мовою залишається актуальним науковим завданням. Під поняттями будемо розуміти терміни-іменники, а також іменні групи, що мають визначення в спеціалізованих словниках термінів предметної області або у самому тексті природною мовою. Архітектура підсистеми мережевого засобу (у вигляді веб-сервісу з API) представлена у вигляді конвеєру обробки електронних текстових документів, що містять природномовний текст (Рис. 1), та складається з наступних етапів та компонентів:
1. Екстракція тексту з документів форматів .pdf, .docx, .doc.
2. Базова нормалізація тексту – так званий лінгвістичний препроцесінг
3. Перевірка орфографії тексту та автоматичне виправлення помилок.
Рисунок 1 – Конвеєр обробки електронних текстових документів.
4. Лексичний аналіз– токенізація (Tokenizing) – в загальному випадку це процес перетворення послідовності символів в послідовність токенів.
5. Граматичний аналіз – розмітка тексту частинами мови, в загальному випадку це процес присвоєння синтаксичної категорії кожному з токенів.
6. Морфологічний аналіз – в загальному випадку це процес лематизації. Синтаксичний аналіз – парсинг та чанкінг, в загальному випадку це процес аналізу речення, який спочатку визначає їх складові частини, а потім зв’язує їх з одиницями вищого порядку, які мають дискретні граматичні значення. Виділені іменники та іменні групи перевіряються за спеціалізованими словниками предметної області та за наявністю їх визначень у реченнях тексту.
7. Формування спеціалізованих XML-структур та HTML-структур тексту. Для реалізації цього етапу розроблені відповідні функції та процедури, що дозволяють отримати у вигляді вихідних даних результати конвеєру обробки електронних текстових документів.
8. Програмно-інформаційні засоби, які визначають функціональність конвеєру обробки електронних текстових документів, забезпечують вирішення завдання автоматизованої обробки природномовних текстових документів українською мовою на основі лінгвістично-семантичного аналізу наданих вихідних даних.
Наступним кроком є вибір алгоритму кластеризації. Хоча є кілька популярних, серед них K-means і DBSCAN, Majorclust дещо менш відомий, але має важливу перевагу: він не вимагає критеріїв припинення, таких як кількість кластерів, кількість елементів у кластері або максимальна відстань між елементами в кластері, які мають бути встановлені заздалегідь. В багатьох завданнях NLP (англ. Natural Language Proccessing), таких як кластеризація слів (або інших сутностей природної мови, зокрема, понять), їх дуже важко вгадати, навіть через багато експериментів. Majorclust – це новий метод, вперше описаний у [1] для програмного застосунку кластеризації документів. Алгоритм починається з присвоєння кожному документу окремого кластера. На кожній ітерації кожен документ призначається до кластеру, з яким він має найбільшу схожість. Схожість документа з кластером розраховується як сума косинусної схожості документа з кожним з членів кластера. Таким чином, документ може бути повторно кластеризовано в інші кластери на наступних ітераціях. Кластеризація припиняється, коли жоден документ не змінює свій кластер. У нашому випадку необхідні дві модифікації цього алгоритму. По-перше, якщо багато елементів у матриці мають ненульову подібність з багатьма іншими елементами (наприклад, вектори слів мають багато ненульових значень в тих самих стовпцях, як у випадку з векторами word2vec), то Majorclust може в кінцевому підсумку помістити всі елементів в один кластер. Тому необхідно було ввести поріг, нижче якого схожість скасовується, тобто встановити 0. Після деяких експериментів ми виявили, що хороших результатів можна досягти, видаливши до 99% найменших пар подібності. По-друге, після скасування малої подібності буде багато елементів, не схожих на будь-який інший елемент. Тобто кожен з них повинен або становити окремий кластер, або розглядатися як шум. Majorclust об’єднає два елементи разом, навіть якщо подібність між ними дорівнює 0, створюючи таким чином один великий всеохоплюючий кластер з великою кількістю непов’язаних слів. Тому інша модифікація полягає в тому, щоб запобігти присвоєнню елементу кластеру, якщо його подібність дорівнює 0. Наша реалізація вимагає, щоб усі значення подібності були рівними або більшими за 0, тому спочатку ознаки у векторах потрібно масштабувати до діапазону, наприклад, (0, 1).
Розробка та навчання прогностичних моделей дистрибутивної семантики для української мови з використанням алгоритму word2vec та інших, наведено у роботах [2, 3, 4]. Розроблено експериментальну реалізацію алгоритму Majorclust з word2vec-моделями для кластеризації слів. Виділенні поняття формують мережеву модель представлення знань відповідної предметної галузі.
Висновки. В роботі розглянуто алгоритм та програмна реалізація науково-дослідного модулю підсистеми підсистеми дистрибутивно-семантичного аналізу текстових документів українською мовою та виділення і кластеризацію наявних понять, з використанням алгоритмів word2vec та MajorClust. На теперішній час, актуальна версія сервісу доступна за посиланням та вільна для використання в науково-дослідних та педагогічних цілях: https://konspekt.ai-service.ml/ua. Експериментальна реалізація алгоритму Majorclust з word2vec-моделями для кластеризації слів доступна за посиланням: https://gist.github.com/malakhovks/a8b2e895a755419bc49b21e888267e2f.
Список використаних джерел:
1. Stein, B., S. M. Eissen. Document Categorization with MajorClust. In: Proc. 12th Workshop on Information Technology and Systems, Tech. Univ. of Barcelona, Spain, 2002, 6 pp.
2. An NLU-Powered tool for knowledge discovery, classification, diagnostics and prediction. URL: https://ukrvectores2.ai-service.ml.
3. Palagin, O.V., Velychko, V.YU., Malakhov, K.S., Shchurov, O.S. 2020. Distributional semantic modeling: a revised technique to train term/word vector space models applying the ontology-related approach. In: Proceedings of the 12th International Conference of Programming UkrPROG 2020. CEUR Workshop Proceedings 2866. Kyiv, Ukraine, September 15-16, 2020.
4. Palagin, O.V., Velychko, V.YU., Malakhov, K.S., Shchurov, O.S. 2018. Research and development workstation environment: the new class of current research information systems. In: Proceedings of the 11th International Conference of Programming UkrPROG 2018. CEUR Workshop Proceedings 2139. Kyiv, Ukraine, May 22-24, 2018. Available from: http://ceur-ws.org/Vol-2139/255-269.pdf.
|