Сфера охорони здоров’я часто стає об’єктом дослідження низки наукових спільнот. Проте значна більшість із них сконцентровані на вивченні та автоматизації процесів діагностики та лікування, в той час як критично мало уваги приділено ефективному зберіганню та структуризації медичних даних усіх пацієнтів. Зараз, щоб полегшити збір даних, ця інформація часто збирається в електронних системах управління у вигляді текстових приміток вільної форми. Недоліком такого простого збору даних є відсутність структури, що ускладнює визначення діагнозу, підбір належного лікування для пацієнта. Метою збору даних у контексті обсерваційних досліджень є уможливлення порівняння типових реакцій та аналізів між досліджуваними групами із різним шляхом лікування задля простеження залежностей. У цих умовах значна варіативність збору клінічних даних деструктивно впливає на їх надійність, адже сповільнює та обтяжує пошук та аналіз цих даних.
Досі проведені дослідження пропонували організацію системи збору даних на основі блокчейну та хмарного сховища [1]. Науковці визначили, що через те, що дані зберігаються централізовано, у різних медичних установах, головною проблемою стає слабкість у надійності обміну даними між лікарнями. Запропонований метод передбачав, що кожна подія (транзакція) представляється у вигляді незмінного chain-запису, до неї додається часовий показник та хеш попереднього блоку, після чого вона стає частиною неперервного ланцюга між сторонами обміну цими даними. У непермісивному блокчейні всі сторони можуть переглядати всі записи, тоді як у пермісивному блокчейні конфіденційність можна налаштувати, вказавши обмеження на доступ до групи даних за відсутності відповідного сертифікату. Попри те, що з першого погляду здається оптимальним збереження усіх медичних даних безпосередньо у блокчейні, це має ряд недоліків, такі як висока вартість та обмеження розміру збережених даних. Саме тому у блокчейн передається лише індексна інформація медичних записів та транзакцій. Система передбачає збереження не лише приватних даних пацієнтів, але й публічну інформацію про медичні установи. Відповідно до цього, при створенні нових записів про пацієнта, користувачі мають змогу згенерувати публічний та приватний ключ, зашифрувати ці записи, використовуючи хеш алгоритми, а отримавши приватний ключ від медичного закладу, пацієнт має змогу їх дешифрувати. Проте головним недоліком такої системи є її невиправність, адже хеш кожного блоку ланцюга зберігається у попередньому, а змінивши дані, хеш блок теж автоматично перегенеровується, що відповідно суперечить головній концепції блокчейну.
Науковці з Університету Торонто працюють над розробкою платформи [2] одним з основних компонентом якої є NCR (Neural Concept Recognizer) [3], завдяки якому стають можливими змістовні пошук та аналіз, адже в його основі лежать медична онтологія та анотації обробки природної мови. NCR використовує згорточну нейронну мережу для кодування вхідних фраз і подальшого ранжирування медичних концепцій на основі подібності в цьому просторі, асоційованому з даними на момент входу.
Використовуючи за основу JCR (Java Content Repository) [4], що являє собою дерево вузлів із коренем jcr:root, було сконструйовано універсальну модель бази даних. Застосування цього API виділяє, що кожен вузол складається із властивостей (properties) та дочірніх вузлів (child nodes), що в свою чергу зберігають фактичний вміст вузла через значення своїх змінних та визначають структуру даних відповідно. Що важливо – JCR через ACLs (resource-based Access Control Lists) дозволяє обмежувати доступ до різних груп вузлів та їх властивостей у залежності від ролі користувача. JCR API надає перелік дозволів, що мають назву привілеї ("privileges") та визначають набір дозволених операцій для створення, читання, зміни та видалення.
Головною концепцією Resource-based ACLs є здатність до наслідування дочірніми ресурсами Access-control списку, тобто кожен похідний від ресурса об’єкт матиме в своєму стеці той же список доступів для груп користувачів. Попри це, даний підхід має і певні недоліки, адже через те, що усі доступи зберігаються безпосередньо в ресурсі, це має досить громіздкий вигляд та може займати додатковий резерв пам’яті.
Для основних маніпуляцій було обрано 4 головні кореневі типи об’єктів Node – Subjects, Subject types, Forms, Questionnaires (Рис. 1).
При реєстрації нового користувача спершу перед нами постає суб’єкт (Subjects), що на початковому етапі представлений самим пацієнтом, проте за своїм визначенням є досліджуваною сутністю, про яку ведеться запис даних. Тут слід ввести у використання термін – тип суб’єкту (Subject type), адже під цим об’єктом зберігатиметься список дозволених типів, таких як пацієнт, пухлина, область пухлини або ж просто візит.
У залежності від створених попередньо суб’єктів, пацієнт або його лікар отримує доступ до заповнення визначених анкет (що у системі зберігається як Questionnaire) і створює форму (Form) (рис.1). Згідно із потребами кожна анкета може бути кастомізована такими ознаками (properties) як максимальна/мінімальна кількість створених форм для суб’єкта, дозволений тип суб’єкта та іншими. Від кожного Questionnaire походить список дочірніх об’єктів – питання (Question) та секції (Section), що об’єднує певну логічну групу питань. В свою чергу Question своїми properties задає безпосередньо питання (text), свій опис (description) та правила заповнення, такі як тип введених даних (dataType), режим відображення (displayMode), мінімальна (minAnswers) та максимальна (maxAnswers) кількість відповідей.
У відповідність до них форма містить відповідь (Answer) та секцію відповідей (Answer Section). Кожна форма серед своїх проперті обов’язково містить questionnaire із id-reference відповідної анкети, а відповідь та секція відповідей як об’єкти, окрім значення зберігають посилання на question та section.
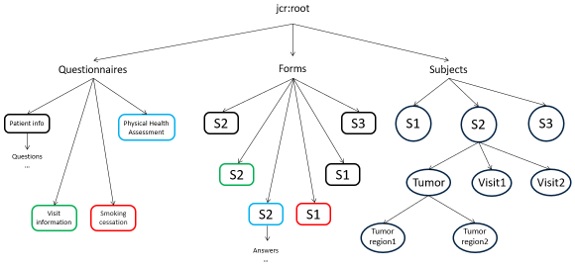
Рис.1. Структура збереження даних
Оскільки кінцевим користувачем платформи є пацієнт або ж працівник лікарні, то однією з найбільших частин системи є користувацький інтерфейс - frontend для якого був реалізований завдяки React JS та Material UI, а backend - завдяки Apache Sling [5] у комбінації із Apache Jackrabbit Oak [6] та Apache Felix [7]. Через велику варіативність пропонованого функціоналу було вирішено реалізувати модульну розробку, де кожен модуль відповідає одній важливій функції та слабко пов'язаний із іншими, в результаті чого при імплементації нової версії платформи для нового покупця (іншої лікарні) можна було б легко додати та видалити ряд непотрібних функцій.
Важливою властивістю Apache Sling є його базова здатність до модульної серіалізації JSON даних. Цей функціонал було розширено, щоб забезпечити більш гнучку та потужну серіалізацію. Код серіалізації розділений на кілька незалежних компонентів, кожен із яких відповідальний за специфічний стан обробки оригінального ресурсу, що дозволяє їм бути розміщеними у різних модулях. У основі серіалізації лежить процесор (Processor), що розділяє серіалізацію ресурсу на 6 етапів-методів.
Крім того значну частину функціоналу беруть на себе Editors та Vlidators - класи, що викликаються при модифікації чи створенні ресурсу певного типу. На відміну від вищезгаданого Processor, інтерфейси цих класів входять у структуру Apache Jackrabbit Oak, де для них оголошено 8 методів, які можна кастомізувати під свої потреби.
Запропонований спосіб дозволяє інтегрувати у збір та збереження різноманітні та численні типи даних, таких як діагностика пацієнтів, історія лікування, заповнені опитування стану пацієнта чи частково стану пухлини або ж лише її області. Проте розширюючи платформу для різних користувачів, підлаштовуючи її під їхні індивідуальні потреби, виникає потреба у значній перевірці справності раніше реалізованого функціоналу. Для цього науковцям ще потрібно працювати над автоматизацією тестування програмного забезпечення.
Список використаних джерел:
1. Yi Chen, Shuai Ding, Zheng Xu, Handong Zheng, Shanlin Yang (2018) Blockchain-Based Medical Records Secure Storage and Medical Service Framework
2. https://cards.uhndata.io/
3. Arbabi, Aryan, et al. "Identifying clinical terms in medical text using ontology-guided machine learning." JMIR medical informatics 7.2 (2019): e12596.
4. https://jackrabbit.apache.org/jcr/jcr-api.html
5. https://sling.apache.org/documentation.html
6. https://jackrabbit.apache.org/oak/docs/
7. https://felix.apache.org/documentation/documentation.html
|






