Постановка проблеми. Сьогодення характеризується швидким зростанням соціальних медіаплатформ (наприклад, Facebook, Twitter, Instagram, Tumblr тощо), де користувачі можуть публікувати власні думки та погляди на будь-яку тему. Це зростання популярності платформ соціальних медіа перетворило мережу зі статичного сховища інформації на динамічний форум із постійною зміною інформації. Платформи соціальних медіа надали людям можливість висловлювати та ділитися своїми думками та думками в Інтернеті дуже простим способом. Таким чином, так званий User-Generated Content дуже різноманітний, від простих «лайків» до довгих текстових публікацій у блогах стає джерелом великою кількістю неструктурованих даних, яка може бути цінною для різноманітних сфер діяльності, які вимагають розуміння громадської думки щодо того чи іншого явища, ідеї, особи тощо. Типовий приклад, який ілюструє важливість громадської думки: підприємства можуть зафіксувати думку споживачів про свою продукцію або своїх конкурентів. Внаслідок чого цю інформацію можна використовувати для відповідного покращення якості послуг або продуктів. Водночас національні уряди можуть використовувати такі дані як джерело аналізу громадської точки зору щодо різних соціальних питань і відповідно реагувати оперативно.
Однак видобуток думок і настроїв у соціальних мережах дуже складний через величезну кількість даних, отриманих з різних джерел. Уявна інформація про тему прихована в даних, тому людині майже неможливо переглянути різні джерела та отримати корисну інформацію без використання спеціальних інструментів та методик. З цієї причини дослідники почали розробляти підходи, які можуть автоматично виявляти полярність тексту та ефективно видобувати інформацію навіть у величезній кількості неструктурованих даних (наприклад, у вигляді мікроблогів) [1].
Мета дослідження. Виявлення настроїв у Twitter - це нетривіальне завдання і значно відрізняється від виявлення настроїв у звичайних текстах, таких як блоги та форуми. Дослідники, які намагаються розробити ефективні методи TSA, мають зіткнутися з низкою проблем, які виникають через особливі характеристики Twitter. Наприклад, неформальний тип носія та обмеження довжини. Крім того, їм доводиться мати справу з динамічним вмістом, що розвивається. Все це вимагає розробки і застосування алгоритмів і нових підходів, які б дозволяли структурувати дані про настрої аудиторії соціальних мереж з подальшою їх обробкою класичними методами Text Mining.
Результати дослідження. Аналіз настроїв Twitter (TSA) розв'язує проблему аналізу повідомлень, опублікованих у Twitter, з точки зору настроїв, які вони виражають. Twitter є новим доменом для SA і дуже складним. Однією з головних проблем є обмеження на довжину, згідно з яким твіти можуть мати до 140 символів. Крім того, коротка довжина та неформальний тип медіа спричинили появу текстових артефактів (спотворень), які широко зустрічаються в Twitter. Таким чином, методи, запропоновані для TSA, повинні враховувати ці унікальні характеристики.
Мікроблоги – мережева служба, за допомогою якої користувачі можуть ділитися повідомленнями, посиланнями на зовнішні вебсайти, зображеннями або відео, які бачать користувачі, підписані на послугу.
Найважливіші проблеми TSA [2]:
- довжина тексту: однією з унікальних характеристик твітів є їхня коротка довжина, яка може складати до 140 символів; цим TSA відрізняється від попередніх досліджень аналізу настроїв більшого тексту, такого як блоги чи огляди фільмів;
- релевантність теми: більшість робіт, які виконуються над TSA, спрямовані на класифікація сентиментальної орієнтації твіту без урахування тематичної релевантності; щоб зафіксувати актуальність теми твіту, багато дослідників просто вважають присутність слова показником актуальності теми;
- візуальні артефакти: через неформальний тип спілкування та обмеження тривалості повідомлення твіти характеризуються емфатичним використанням верхнього реєстру, емфатичним подовженням, скороченням та використанням сленгу та неологізмів;
- розрідженість даних: твіти містять багато шуму через широке поширення орфографічних помилок, що впливає на загальну ефективність аналізу настроїв;
- заперечення: наявність слів-заперечень відіграє важливу роль у виявленні полярності настрою повідомлення; заперечення можуть спричинити зміну полярності повідомлення (позитивне стає негативним або навпаки);
- токенізація: ще однією проблемою, пов’язаною з TSA, є токенізація речень.
Усі ці виклики є дуже важливими, і їх необхідно враховувати під час організації TSA. Саме тому, поширення набувають методи і алгоритми Text Mining, такі як Opinion Mining (OM) і Sentiment Analysis (SA) – два відносно нових напрямки досліджень, які мають на меті допомогти користувачам знаходити і вилучати інформацію та визначити полярність з неструктурованих текстів. OM і SA зазвичай використовуються як синоніми для вираження того самого значення. Однак деякі дослідники стверджують, що вони прагнуть розв'язувати різні проблеми. Так, OM має на меті визначити, чи містить фрагмент тексту думку або проблему, яка також відома як аналіз суб’єктивності, тоді як у центрі SA лежить безпосереднє виявлення полярності настроїв, за допомогою якої думка досліджуваного тексту позначається як позитивне або негативне.
OM і SA вивчалися на багатьох засобах масової інформації, включаючи огляди, обговорення на форумах та блогах. Останнім часом дослідники почали аналізувати думки та настрої, висловлені в мікроблогах, оскільки вони містять велику кількість думок. Одним із найпопулярніших мікроблогів є Twitter, який зумів залучити велику кількість користувачів, які діляться думками, думками та взагалі будь-якою інформацією на будь-яку тему, яка їх цікавить. Інформація, яка публікується в Twitter, часто містить думки про продукти, послуги, події або будь-що, що цікавить користувача. Завдяки своїй популярності Twitter нещодавно зацікавив багатьох дослідників, які аналізували дані Twitter для різноманітних завдань, таких як прогнозування, виявляючи настрої користувачів щодо різних тем, виявлення емоцій користувачів та виявлення іронії [3].
Повідомлення, які публікуються в мікроблогах, короткі на відміну від традиційних блогів. Одним із найпопулярніших мікроблогів є Twitter, який був запущений у 2006 році і з того часу привабив велику кількість користувачів. Зараз Twitter має 284 мільйони користувачів, які публікують 500 мільйонів повідомлень на день. Завдяки тому, що він забезпечує простий спосіб доступу та завантаження опублікованих публікацій, Twitter вважається одним із найбільших наборів даних вмісту, створеного користувачами. Twitter характеризується деякими особливостями, які перелічені нижче [4]:
- твіт – це одне повідомлення, опубліковане у Твіттері; вміст твіту, який може містити щонайбільше 140 символів, може варіюватися від особистої інформації чи особистої думки про продукти, чи події до інших, таких як посилання, новини, фотографії чи відео;
- користувач/ім’я користувача: користувач має бути зареєстрований на платформі, щоб публікувати твіти;
- під час реєстрації користувач обирає псевдонім (ім’я користувача), який надалі буде використовуватися для розміщення повідомлень;
- згадка: згадки у твіті означають, що в публікації згадується інший користувач; щоб зробити це посилання на ім’я користувача, користувачі використовують символ @, після якого йде конкретне ім’я користувача, на яке вони посилаються (@username);
- відповіді: відповіді у твіті використовуються, щоб вказати, що публікація є відповіддю на інший твіт, і зазвичай використовуються для створення бесід; подібно до згадок, вони створюються за допомогою символу @, після якого йде ім’я користувача, на яке вони посилаються;
- підписуник: підписники – це користувачі, які стежать за твітами та діяльністю користувача; стежити за іншими користувачами – це основний спосіб зв’язатися з іншими користувачами в Twitter;
- ретвіт: ретвіти стосуються твітів, які повторно поширюються; коли користувач вважає твіт цікавим, він або вона може повторно опублікувати його за допомогою функції ретвітів;
- хештег: хештеги використовуються для позначення відповідності твіту певній темі; хештеги, які створюються за допомогою символу #, за яким слідує назва теми (#topic), виникли через необхідність позначати інформацію на опублікованих повідомленнях;
- конфіденційність: Twitter дає користувачеві можливість вирішити, чи будуть його/її твіти видимими для всіх чи лише для його/її схвалених підписників у Twitter.
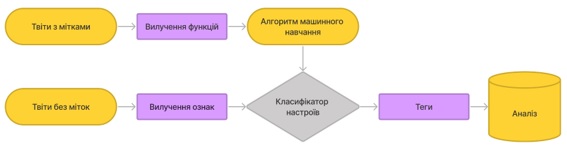
Рис. 1. Типовий процес класифікації настроїв
Більшість методів TSA використовують метод із галузі машинного навчання, відомий як класифікатор. На рис. 1 показано найбільш типовий процес TSA. Перший крок включає збір твітів і позначення їх за настроями. Позначені твіти представляють навчальні дані. Хоча Twitter API (інтерфейс прикладного програмування) полегшує процес збору твітів, присвоєння міток є складним завданням, і до нього слід підходити обережно.
Коли структурована база даних заповнюється інформацією, отриманою з анотованих документів, дані нарешті готові до видобутку. У цьому контексті «видобуток» є синонімом «аналізу», оскільки метою є отримання корисної інформації з текстових даних для створення нових знань. Для цього, враховуючи, що дані тепер у структурованій формі, можна використовувати стандартні статистичні процедури та методи, застосовані до текстових даних, які тепер у структурованій формі. Іноді цей етап повторюються, доки інформація не буде вилучена.
Висновки і перспективи. В результаті проведених досліджень було зв'ясовно, що видобуток тексту для аналізу даних про настрої аудиторії Twitter охоплює пошук інформації, аналіз тексту, безпосереднє вилучення інформації, кластеризацію, категоризацію, візуалізацію, використання методів інтелектуального аналізу баз даних та методів машинного навчання. Все це стає надзвичайно актуальним, особливо при використанні вилученої інформації для покращення якості продуктів або послуг і подальшої адаптації до ринкових вимог.
Список використаних джерел:
1. Giachanou A., Crestani F. Like it or not. ACM computing surveys. 2016. Vol. 49, no. 2. P. 1–41. URL: https://doi.org/10.1145/2938640 (date of access: 16.12.2022).
2. Patodkar V. N., I.r S. Twitter as a corpus for sentiment analysis and opinion mining. Ijarcce. 2016. Vol. 5, no. 12. P. 320–322. URL: https://doi.org/10.17148/ijarcce.2016.51274 (date of access: 16.12.2022).
3. Thelwall M., Buckley K., Paltoglou G. Sentiment strength detection for the social web. Journal of the american society for information science and technology. 2011. Vol. 63, no. 1. P. 163–173. URL: https://doi.org/10.1002/asi.21662 (date of access: 16.12.2022).
4. Twitter: social communication in the Twitter age. Choice reviews online. 2013. Vol. 50, no. 10. P. 50–5424–50–5424. URL: https://doi.org/10.5860/choice.50-5424 (date of access: 16.12.2022).
|






